
Die für mich freigegebenen Datenblätter bieten Zugriff auf die Selligent by Zeta-Standarddaten. Dazu zählen Datensätze, für die jemand verantwortlich ist (einschließlich ich selbst), und Datensätze, für die ich nicht verantwortlich bin. Zurzeit sind folgende Datensätze verfügbar (für einen detaillierten Überblick über die gemeinsam genutzten Datensätze finden Sie unter diesem Thema.):
- Kommunikationsstatistiken: Dieser Datensatz enthält alle Kommunikationen pro Kontakt und alle Interaktionen dazu. Üblicherweise sind Felder, die in diesem Datensatz verfügbar sind, gesendete, zugestellte, angezeigte und angeklickte E-Mails.
- Kommunikationsübersicht: Dieser Datensatz enthält alle Kommunikationen und Interaktionen. Typische in diesem Datensatz verfügbare Felder sind gesendete, zugestellte, angezeigte und angeklickte E-Mails. Dieser Datensatz unterscheidet sich vom Kommunikationsstatistiken-Datensatz darin, dass er keine Daten auf Kontaktebene, sondern nur aggregierte Daten enthält. Dies wirkt sich positiv auf die Leistung aus.
Hinweis: Der Kommunikationsstatistiken-Datensatz und der Kommunikationsübersicht-Datensatz berücksichtigen historische Daten aus den letzten 14 Monaten für das anfängliche Laden. Für alle neuen Interaktionen werden diese jedoch nur berücksichtigt, wenn sie mit Kommunikationen verbunden sind, die diesen oder vorherigen Monat erfolgt sind. Neue Interaktionen bei älteren Kommunikationen sind nicht in den Zusammenfassungen enthalten.
- Verbraucherengagement-Statistiken: Zeigen Sie alle Verbraucher und ihr Engagement an. Dieser Datensatz unterstützt zurzeit die Standardfelder in einer Zielgruppenliste oder 1:1 verlinkte Liste (wie z. B. E-Mail, Sprache, Abmelden, Maildomäne, Abonnieren-Quelle usw.) sowie die gängigsten benutzerdefinierten Felder (wie z. B. Abonnieren-Quelle, Bounce-Zähler, Geschlecht, Geburtstag, Alter, Land, ...).
Hinweis: Die Verbraucher-Datensätze werden bei einer einzigen Zielgruppenliste erstellt. Die Standard-Zielgruppenliste basiert auf der Liste mit der kleinsten ID. Wenn die Statistiken auf einer anderen Zielgruppenliste basieren sollen, muss ein Filter zu ListenID/ListName zum Dashboard hinzugefügt werden und die rechte Liste muss aus dem Dropdown ausgewählt werden.
Datensätze, für die ich verantwortlich bin – vom Benutzer heruntergeladene Datensätze (z. B. eine CSV-Datei oder eine Verbindung zu einer Datenbank wie Google Big Query). Diese Datensätze werden nur vom Benutzer verwaltet. Berechnete Felder können hinzugefügt werden. Der Eigentümer des Datensatzes kann ihn für andere Benutzer freigeben.
Öffentliche Datensätze – Datensätze, die für jeden verfügbar sind. Zum Beispiel eine Weltkarte mit demografischen Informationen. Diese Datensätze sind nicht mit Selligent by Zeta verknüpft und werden zurzeit nicht verwendet.
Datentypen
Die Daten in den Datensätzen können 4 verschiedene Typen sein. Jeder Typ hat ein dediziertes Symbol:
![]() Hierarchie – beschreibt sich gegenseitig ausschließende Dinge wie Geschlecht, Kanaltyp, Journey-Typ usw. Dies können Zeichenfolgen und Ziffern sein und sie können als Kategorien und zum Gruppieren von Daten verwendet werden.
Hierarchie – beschreibt sich gegenseitig ausschließende Dinge wie Geschlecht, Kanaltyp, Journey-Typ usw. Dies können Zeichenfolgen und Ziffern sein und sie können als Kategorien und zum Gruppieren von Daten verwendet werden.
![]() Datum/Uhrzeit – wie z. B. Jahr, Monat, Woche, Tag, Stunde, Minute, Sekunde. Dies zeigt eine Entwicklung im Zeitverlauf und kann auch in Filtern verwendet werden.
Datum/Uhrzeit – wie z. B. Jahr, Monat, Woche, Tag, Stunde, Minute, Sekunde. Dies zeigt eine Entwicklung im Zeitverlauf und kann auch in Filtern verwendet werden.
![]() Maße – nummerische Werte, die in Berechnungen verwendet werden (z. B. gesendete, zugestellte, geöffnete E-Mails). Auf Basis dieser Maße können Aggregate erstellt werden.
Maße – nummerische Werte, die in Berechnungen verwendet werden (z. B. gesendete, zugestellte, geöffnete E-Mails). Auf Basis dieser Maße können Aggregate erstellt werden.
Hinweis: Maße können nicht als Kategorie in einer Grafik verwendet werden.
Topographie – definiert einen Ort (z. B. Längengrad, Breitengrad). Dies wird zum Darstellen von Daten auf Karten verwendet.
Anzeige eines Datensatzes
Um die Details eines Datensatzes anzuzeigen, klicken Sie in der Übersicht des Datensatzes darauf:
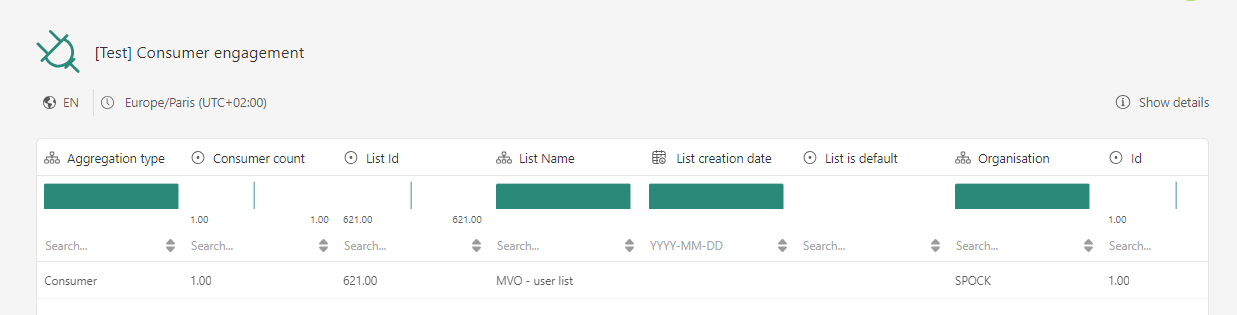
Die Struktur und die Daten des ausgewählten Datensatzes werden angezeigt:
Erstellen eines berechneten Felds
Sie können Ihre eigenen berechneten Felder auf Basis Ihres eigenen Datensatzes und auf Basis von Datensätzen, die für Sie freigegeben werden, erstellen.
Um ein berechnetes Feld zu erstellen, öffnen Sie den Datensatz Ihrer Wahl.
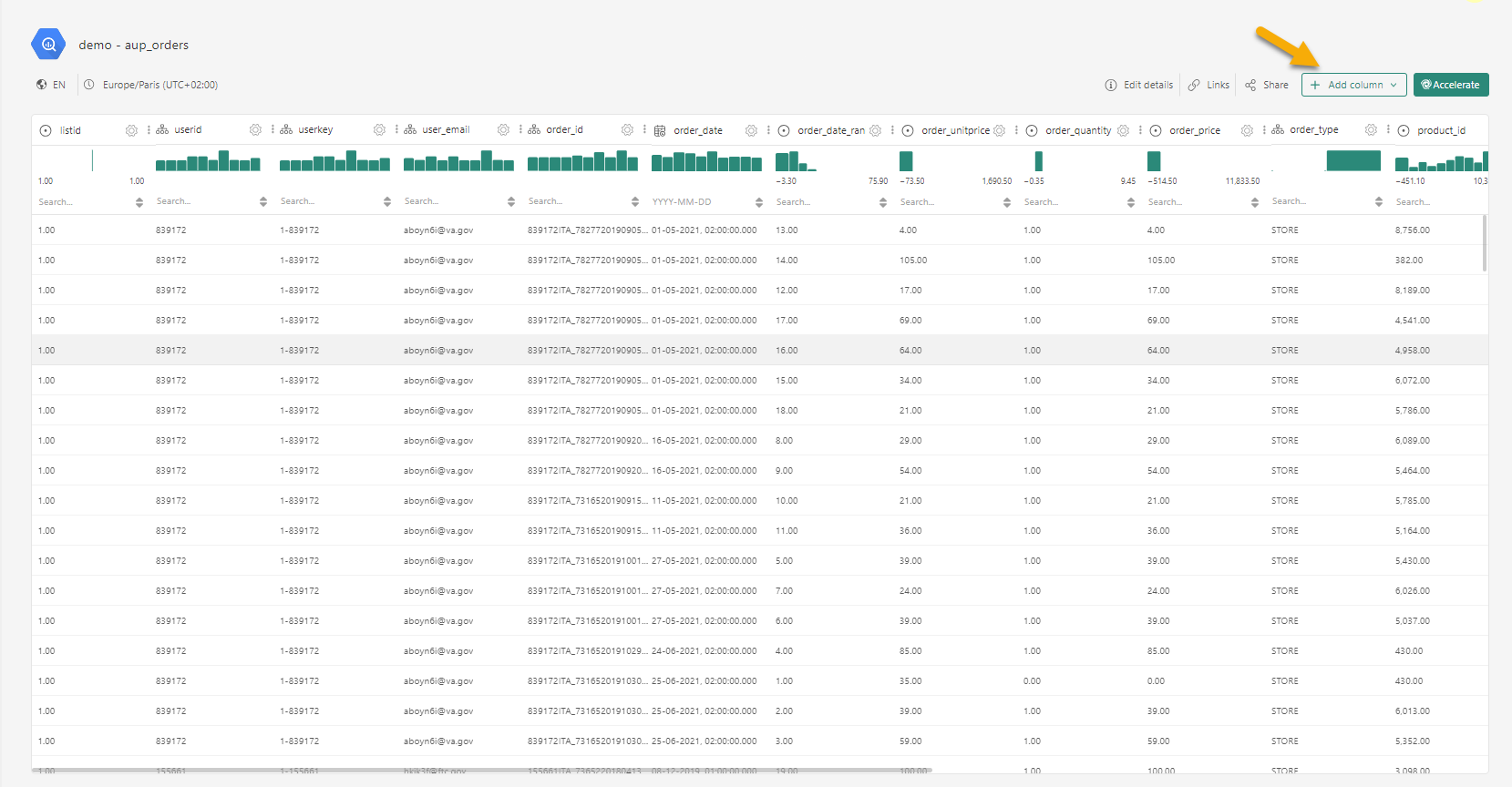
Klicken Sie auf „Spalte hinzufügen“ und konfigurieren Sie das berechnete Feld:
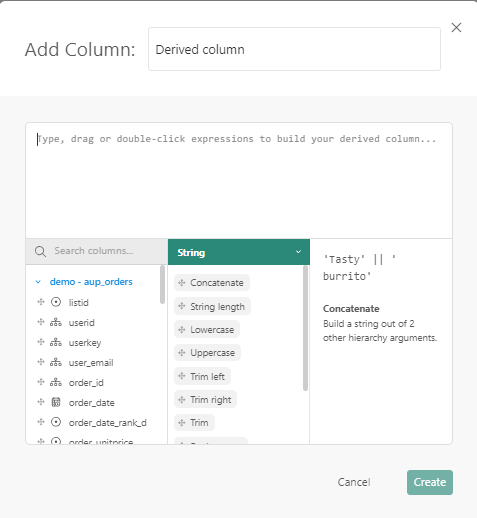
Links können Sie die Spalten im Datensatz verwenden und sie zum weißen Bereich oben ziehen.
Der mittlere Abschnitt ermöglicht das Auswählen der anzuwendenden Funktion. Das Dropdown-Feld oben ermöglicht die Auswahl zuerst des Funktionstyps (Zeichenfolge, mathematisch, Konversion usw.) und anschließend der Funktion. Eine Erklärung, was die Funktion tut, und der Parameter ist rechts verfügbar. Ziehen Sie die ausgewählte Funktion auf den weißen Bereich oben und legen Sie sie ab.
Beispiel:
Verwenden Sie die Spalte Journey_Type und wenden Sie eine bedingte Funktion „IsEmpty“ an, wo leere Werte durch den Wert „Unknown“ ersetzt werden. Beim Auswählen der Funktion und Ablegen auf dem Bereich sind Platzhalter verfügbar, auf die Spalten abgelegt werden können.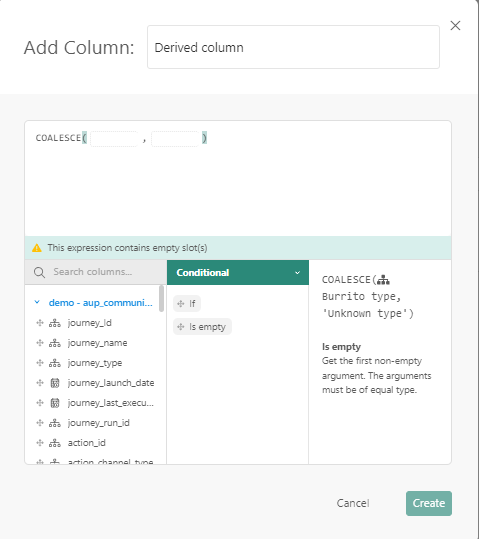
Ziehen Sie die Spalte Journey_type auf den ersten Platzhalter und geben Sie einen Wert für den zweiten Platzhalter ein.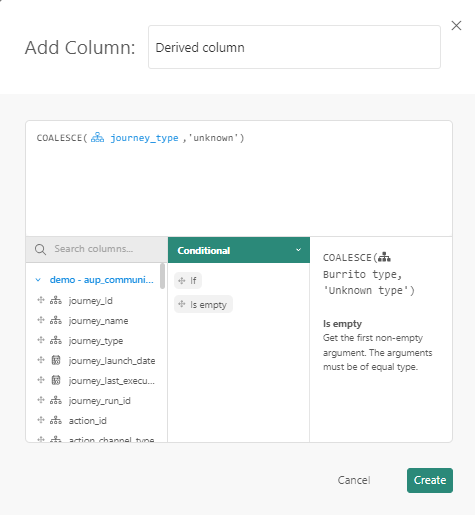
Erstellen eigener Datensätze (nur für Selligent Data Studio Pro)
Benutzer von Selligent Data Studio Pro haben die Möglichkeit, ihre eigenen Datensätze aus mehreren verschiedenen Quellen zu erstellen. Gehen Sie dazu zur Registerkarte „Datensätze“ in Selligent Data Studio.
Es sind mehrere Optionen verfügbar:
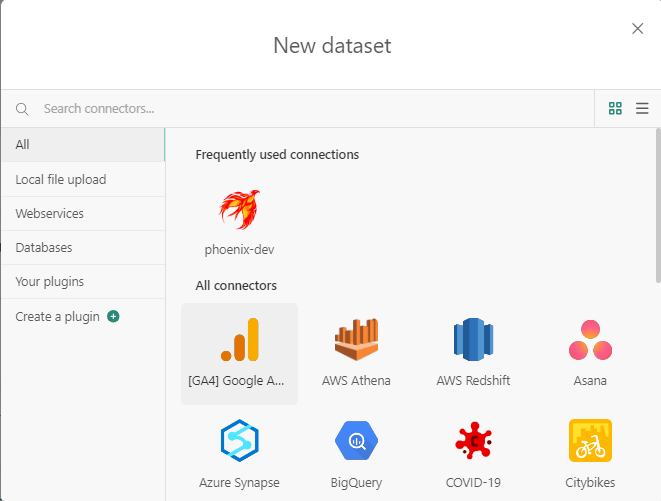
- Upload einer lokalen Datei als CSV-Datei
- Webdienste wie Google Analytics und Google Drive
- Datenbanken wie SQLServer, MySQL usw.
- Plugins wie BigQuery
Je nach ausgewähltem Verbindungstyp müssen verschiedene Parameter ausgefüllt werden.
Hinweis: Beim Laden von Daten aus einer CSV-Datei in den Datensatz muss dieser Vorgang regelmäßig erneut ausgeführt werden, um die Daten aktuell zu halten. Wenn Sie jedoch eine Verbindung zu einem Cloud-Datenspeicherort herstellen, sind die Daten immer auf dem neuesten Stand.
Google Analytics

Sie werden von Google aufgefordert, sich anzumelden, um Zugriff auf Ihre Analytics-Daten zu gewähren. Wenn Sie nicht der Eigentümer des Google Analytics-Kontos der Site („Web-Eigentum“) sind, stellen Sie sicher, dass die E-Mail-Adresse, mit der Sie sich bei Google anmelden, zumindest Leseberechtigungen hat.
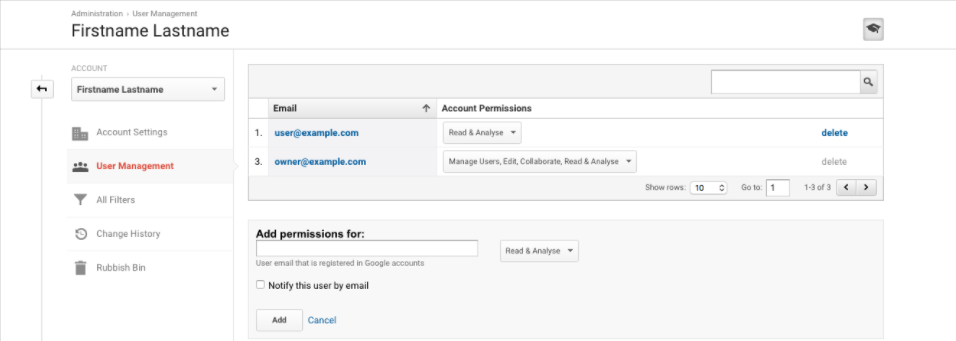
Nach dem Akzeptieren sollten Sie Daten direkt aus Google Analytics importieren können.

BigQuery
Richten Sie zuerst ein Dienstkonto ein, um auf BigQuery zuzugreifen:
Gehen Sie zur Google Cloud-Konsole und wählen Sie die Registerkarte „IAM & Admin“ im linken Menü aus. Klicken Sie auf „Dienstkonten“ in der Liste.

Klicken Sie auf „Create new service account“ und geben Sie diesem einen Namen Ihrer Wahl. Wählen Sie aus dem Rollen-Dropdown „BigQuery Admin“ aus und markieren Sie „Furnish a private key“.
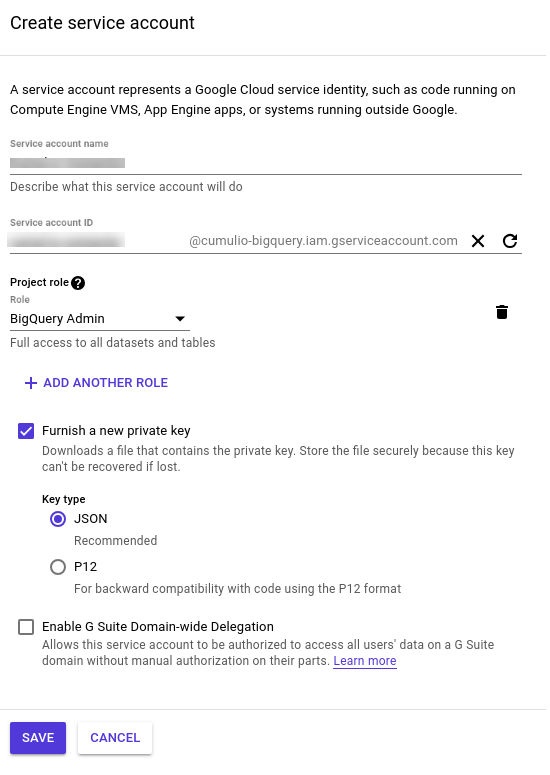
Nach dem Erstellen wird automatisch eine JSON mit Anmeldeinformationen heruntergeladen.
Gehen Sie zur Registerkarte „Datensätze“ und klicken Sie auf „Neuer Datensatz“. Wählen Sie den „BigQuery“-Connector aus. Sie werden aufgefordert, einen Schlüssel und ein Token anzugeben. Kopieren Sie diese wortwörtlich aus der JSON-Datei:
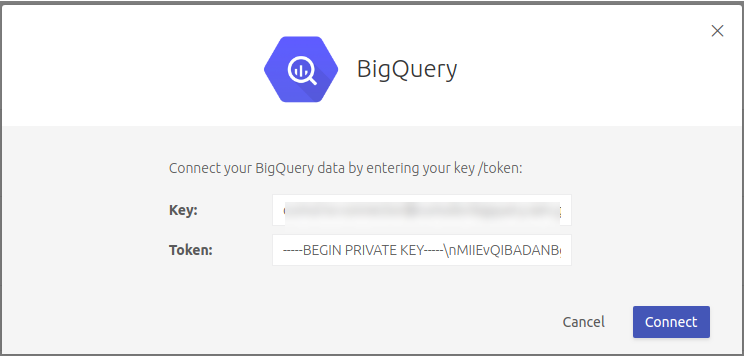
Kopieren Sie den Wert des JSON-Felds client-email als Schlüssel.
Kopieren Sie den Wert des JSON-Felds private-key als Token.
Oracle-Client
Gehen Sie zur Registerkarte „Datensätze“ und klicken Sie auf „Neuer Datensatz“. Wählen Sie den „Oracle“-Connector aus. Sie werden aufgefordert, einen Host, einen Schlüssel und ein Token anzugeben:
- Host: Dies ist die Abfragezeichenfolge zum Verbinden mit der Oracle-Datenbank, z. B. my-oracle-host.com:1521/database-sid
- Key: Der Benutzername des Oracle-Benutzers. Wir raten zur Erstellung eines getrennten technischen Benutzers mit Nur-Lesezugriff für das Verbinden von Cumul.io mit Ihren Oracle-Datenbanken.
- Token: Das Passwort des Oracle-Benutzers.
Nach dem Verbinden können Sie Ihre Oracle-Daten auswählen, sich verbinden und sie visualisieren.
Hinweis: Achten Sie darauf, den folgenden Bereich der IP-Adressen in Ihrem Oracle-Server auf die Whitelist zu setzen, wenn externe Verbindungen blockiert sind:
88.99.71.232 ( proxy-a.cumul.io)
52.213.28.47 ( proxy-b.cumul.io)
